The AI Data
Translation Layer.
Turning messy, unstructured data into information that AI models can actually work with.
trusted by teams from startups to enterprises








the problem
AI is ready.
Your data isn't.
The biggest blocker to useful AI isn't the model. It's the gap between what AI needs and what your data actually is.
Your AI projects keep stalling. Not because the model is bad, but because it can't access what it needs. PDFs, contracts, reports, tickets, SharePoint folders, databases, APIs, spreadsheets. None of it is AI-readable by default.
You end up with an expensive model answering from its training data, not from yours. Or worse, hallucinating something that looks right but isn't.
The data exists across many sources and formats. It just hasn't been translated into context that AI can actually use.
The problem isn't the model. It's the missing context layer.
You're building a chatbot, an agent, a knowledge tool. You need it grounded in real data from real sources, not model memory.
Building the context layer yourself means months: chunking strategies, embedding pipelines, reranking, hallucination mitigation, multi-tenant auth, citation tracking. All of it solved problems.
Connect your data sources, call /ask, get a sourced answer. The context layer is already built.
how it works
Not just retrieval.
A full reasoning pipeline.
Most tools return fragments from a single source and leave you to figure it out. RenBase reads your data, understands the relationships across sources, and reasons across all of them before returning an answer.
Every output goes through a critic agent that checks faithfulness and completeness. If it doesn't pass, the system tries again. You never see an answer that hasn't been verified.
setup
From your data sources to a working AI in minutes.
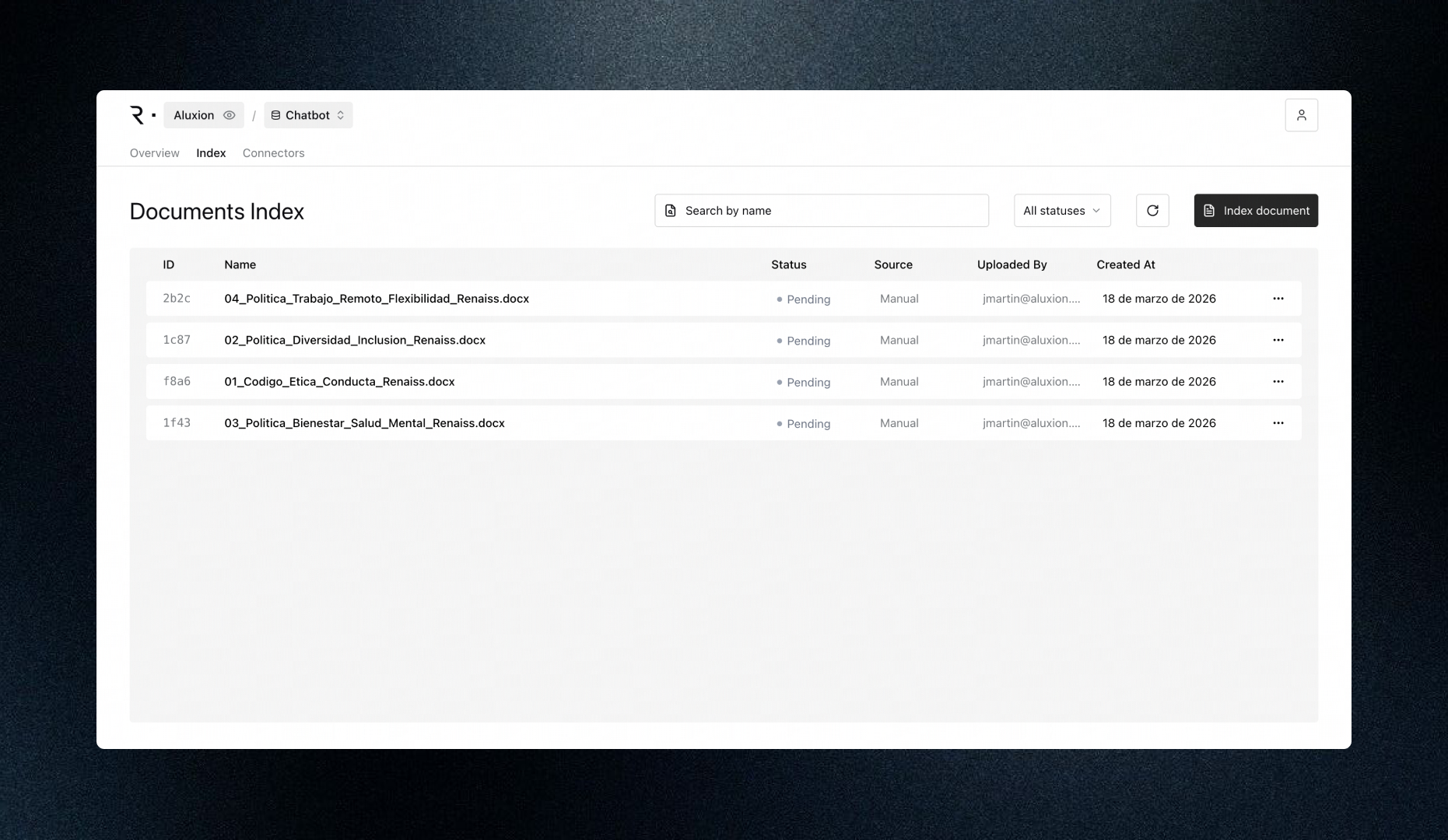
Connect your data sources
PDFs, Word, PowerPoint, spreadsheets, databases, APIs, plain text. Drag and drop or connect programmatically. RenBase processes everything automatically.
Configure your context
Set roles, prompts, access rules, and instructions for your use case. Define who can ask what, and what tone and scope the answers should follow.
Get sourced answers
Not a list of fragments. A direct answer with the exact passage from the exact source, verified by the critic agent before it reaches you.
Section 4.2 sets a 24-month retention limit for inactive accounts…
↗ DPA_v3_2024.pdf · §4.2 · p.18
use cases
Four ways to use RenBase.
Every use case has the same core need: AI that reasons from your actual data sources, not from model memory.
Chatbots with knowledge
"What does our return policy say about items purchased during a promotional period?"
Deploy chatbots grounded in your actual documentation. Consistent, sourced answers for both employees and customers, with no improvisation.
Compliance processes
"Which GDPR articles apply to our data retention practices for EU customers?"
Deterministic workflows that find, verify, and document regulatory requirements. Every answer is auditable and traced to the source.
Knowledge platforms
"What did we agree with that supplier regarding delivery timelines last quarter?"
A single place where anyone can query everything that's been written. Contracts, reports, tickets, threads, docs. All of it searchable.
Any AI agent
"Find all open obligations from contracts signed in 2024 that expire before June."
RenBase as an MCP server. Give any AI agent persistent, verified access to your documents without building the retrieval layer yourself.
for developers
Three lines of code.
One sourced answer.
The API is designed to be obvious. Connect your data sources, ask questions, get structured answers with citations. No configuration, no infrastructure to manage.
// Request
POST https://api.renbase.ai/api/v1/ask
Authorization: Bearer sk_live_••••••••
{
"query": "What are the delay penalties in the Acme contract?",
"base_id": "550e8400-e29b-41d4-a716-446655440000",
"max_sources": 5
}
// Response
{
"answer": "Section 12.3 specifies a 1.5% daily penalty...",
"confidence": 0.95,
"citations": [{
"text": "...a daily penalty of 1.5% of the contract value...",
"source": "Acme_Contract_2024.pdf",
"relevance_score": 0.97
}],
"latency_ms": 1840
}pricing
Start free.
Scale when you're ready.
per month
- 35,000 units / month
- 5M tokens storage
- Sourced answers with citations
- Multilingual support
- Knowledge graph
Overage: $2.00 / 1k units
per month
- 270,000 units / month
- 20M tokens storage
- API access
- Everything in Hobby
- Priority processing
Overage: $1.50 / 1k units
per month
- 900,000 units / month
- 50M tokens storage
- Multiple users & roles
- Team analytics
- Everything in Builder
Overage: $1.00 / 1k units
Contact us
- Unlimited units
- Custom token storage
- On-premise / BYOC
- SSO & audit logs
- Dedicated support & SLA
All plans include: mandatory citation · multilingual (EN / ES / PT / FR / DE / IT) · knowledge graph · critic agent